on
2019 NAVER AI HACKATHON SPEECH 참가 후기
2019년 9월 중순부터 10월 중순까지 약 한 달가량 진행된 NAVER AI HACATHON에 참여하였습니다! 이번 해커톤의 주제는 한국어 음성인식으로 네이버에서 공개한 50000쌍의 한국어 전화망 데이터를 이용해 진행하였습니다. 대학교 친구인 박승일군과 함께 행복코딩 팀으로 참여해 100팀 중 9등이라는 성과를 거두었습니다! 와아~ ![]() 처음 참가해보는 해커톤이였고 음성인식분야도 잘 몰랐었는데 좋은 성적을 거두어서 기분 좋게 마무리 할 수 있었습니다. 참가신청부터 결선까지 어떻게 준비하고 참여하였는지 후기로 남겨보려고 합니다.
처음 참가해보는 해커톤이였고 음성인식분야도 잘 몰랐었는데 좋은 성적을 거두어서 기분 좋게 마무리 할 수 있었습니다. 참가신청부터 결선까지 어떻게 준비하고 참여하였는지 후기로 남겨보려고 합니다.
배경지식 탐색
서류 통과 메일을 받은 후부터 본격적으로 Speech Recognition 분야를 survey 해보았습니다.
제일 먼저 이 부분의 SOTA를 찾아보기위해 Paper with code 사이트에서 Dataset별로 어떤 연구가 진행되었는지 찾아보았습니다.(Paper with code 짱짱 ㅎㅎ)
그 후 우선적으로 다음 논문들을 읽어보았습니다.
또한 Deep Speech를 만든 바이두에서 강연한 영상이 있는데 기존의 전통적인 Speech Recognition 방식에서 벗어나, 어떻게 딥러닝을 사용해 성공적으로 성능을 끌어 올렸는지 쉽게 설명해주십니다. CTC loss, Language Model 등 Deep Speech에서 사용된 개념뿐만 아니라 음성인식 분야에 전반적인 이해를 돕는 영상이라 처음 이 분야를 공부하시려는 분들한테 강추드립니다! ![]()
Deep Speech, Deep Speech 2는 CTC loss를 사용하였고 Listen, Attend and Spell은 encoder-decoder 방식을 사용하였습니다. 저는 survey 당시 SOTA였던 SpecAugment 방식을 사용하고 싶었고 Naver에서 제공한 baseline code도 encoder-decoder 방식을 사용하고 있었기 때문에 encoder-decoder 방식을 사용하기로 결정하였습니다.
예선
NSML
예선이 시작하고 제일 당황스러웠던 것은 로컬에서 잘 돌아가는 모델이 NSML(Naver에서 제공한 딥러닝용 클라우드)에 올리면 잘 안돌아가는 것이였습니다. Librosa 라이브러리를 사용해 mel-spectrogram으로 변환하려고 하였는데 segmentation 오류가 나면서 세션이 죽어버리곤 했습니다. 아무리 디버깅을 해도 이유를 알 수 없어 포기하고 torchaudio를 쓰려던 차에 library간 버전 충돌 때문임을 알고 docker 설정을 바꿔 해결하였습니다.
모델 구조 수정, Data 전처리, label smooth
예선 초반에 Listen, Attend and Spell 방식으로 encoder-decoder에 attention을 달고 테스트 해보니 6등으로 출발했습니다. 본선 진출은 문제 없겠다라고 생각했는데 그 이후로 시도하는 것마다 성능 향상을 보이지 못해 28등까지 떨어졌습니다. 이때 이번 해커톤에서 결과를 평가할때 공백을 제거하고 비교하는 점에서 착안해 모델이 아예 공백을 예측하지 않도록 바꾸니 큰 성능향상이 이뤄져서 등수를 많이 올릴 수 있었습니다. 추가로 label smooth, 데이터 전처리(특수문자 제거) 등을 통해서 성능을 더 올려 예선을 8위로 마무리하였습니다.
결선
결선은 온라인 결선과 오프라인 결선으로 나누어 진행되었습니다. 온라인 결선에서는 예선에서 제공되었던 3만쌍에 데이터에다 추가로 2만쌍의 데이터가 더 공개되었습니다.
오프라인 결선
오프라인 결선은 춘천에 있는 네이버 커넥트원 건물에서 진행되었습니다. 처음 들어가자마자 토니 스타크가 살 것 같다고 말했을 만큼 건물이 깔끔하고 멋있게 지어져 있더라고요
 처음 갔을때 받은 명찰과 웰컴 기프트에요! 저 초록색 동그란 건 손목 운동할 때 쓰는 거더라고요.
처음 갔을때 받은 명찰과 웰컴 기프트에요! 저 초록색 동그란 건 손목 운동할 때 쓰는 거더라고요.
 해커톤 기간동안 무제한으로 먹을 수 있던 간식입니다! 그런데 저 간식 말고도 중간에 떡볶이, 튀김, 콜팝, 치즈볼등 맛있는 간식들을 너무 많이 주셔서 저것들은 별로 안먹었던거 같아요!
해커톤 기간동안 무제한으로 먹을 수 있던 간식입니다! 그런데 저 간식 말고도 중간에 떡볶이, 튀김, 콜팝, 치즈볼등 맛있는 간식들을 너무 많이 주셔서 저것들은 별로 안먹었던거 같아요!

 점심과 저녁입니다. 정말 정말 맛있었어요 ㅎㅎ 역시 대기업인가 싶더라고요. 덕분에 맛있게 먹고 해커톤에 집중할 수 있었습니다!
점심과 저녁입니다. 정말 정말 맛있었어요 ㅎㅎ 역시 대기업인가 싶더라고요. 덕분에 맛있게 먹고 해커톤에 집중할 수 있었습니다!
 숙소도 너무 좋았어요. 호텔에 와있는 느낌 ㅎㅎ 클로바 스피커도 처음 사용해 봤는데 너무 신기하더라고요. 이번 해커톤 주제가 음성인식이라 더 신기했던거 같아요.
숙소도 너무 좋았어요. 호텔에 와있는 느낌 ㅎㅎ 클로바 스피커도 처음 사용해 봤는데 너무 신기하더라고요. 이번 해커톤 주제가 음성인식이라 더 신기했던거 같아요.
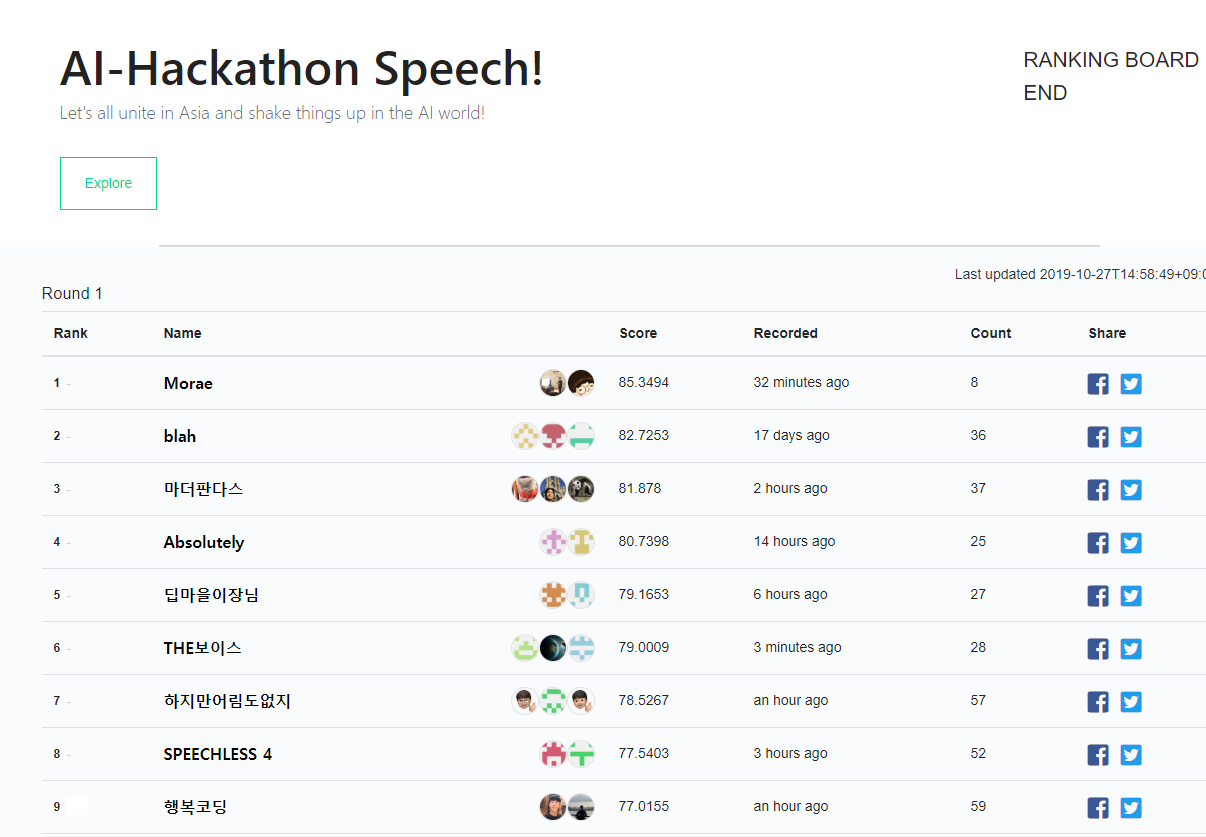
오프라인 결선 기간 동안 어떻게 모델을 개선할지 고민을 많이 했어요. 결론적으로 예선 기간동안 구현했지만 이상하게 성능이 오르지 않았던 빔서치를 좀 더 살펴보았습니다. 그러던 중 빔서치 로직에서 버그를 찾을 수 있었고 버그를 고치니 인식률이 4퍼센트 가량 올랐습니다! 결국 오프라인 결선 시작할 때 11등까지 떨어졌었는데 다시 올려 9등으로 마무리하였습니다. ㅎㅎ
오프라인 결선이 끝나고 1, 2, 3등 팀과 질의 응답시간이 있었습니다. librosa를 이용해 음성파일 앞, 뒤에 있는 침묵을 제거했다는 점, naver에서 weight initialization 관련해서 함정코드를 심어놓았다는 점이 인상깊었습니다. 그리고 무엇보다 1등팀이 training set, valid set을 나눌 때 화자, 스크립트를 고려해서 나눈점이 인상깊었습니다. 해커톤 기간 내내 validation error 와 test error가 비례하지 않아서 이상하다고 생각했는데 화자 및 스크립트에 overfitting 된 점이 문제였습니다. 기본이지만 간과하고 있던 부분이였습니다.
느낀점
이번 해커톤에 참여하여서 처음으로 딥러닝 분야 중 한 task에 몰두해서 모델을 학습시키고 개선해보았습니다. 스피치 분야의 매력도 새롭게 알게 되었고 관심을 갖게 되었습니다.
또한 성능향상을 위해 모델에만 집중하였는데 결국 모델을 향상시키기 위해선 데이터를 잘 이해하는것이 우선인 것을 다시 한 번 깨닫게 되었습니다. weight initialization과 같은 deep learning의 기본의 중요성도 다시 깨닫게 되었습니다.
제가 많이 성장할 수 있었고 무엇보다 즐겁게 참여하여서 너무 행복한 시간이였습니다.
좋은 행사를 마련해준 네이버측에 감사를 표합니다!
추가로 저희팀의 코드 레포지토리 링크를 첨부합니다